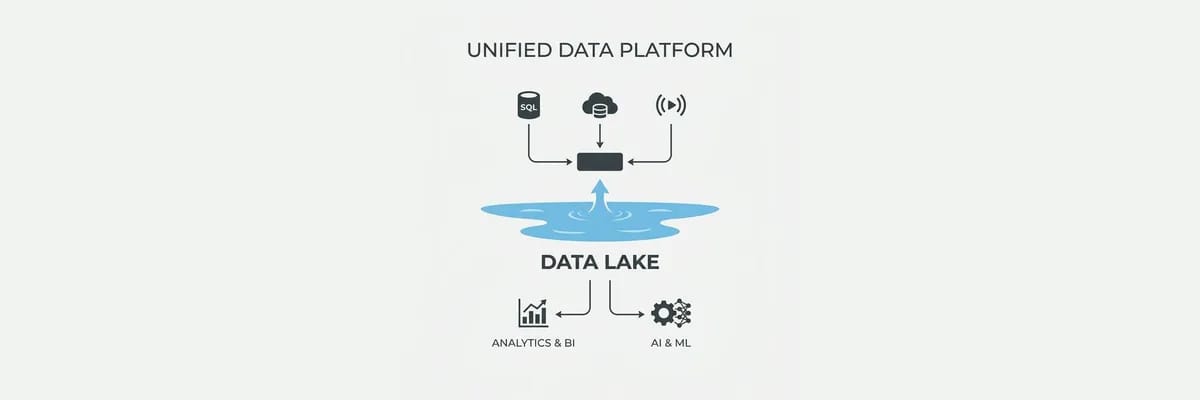
Microsoft Fabric and OneLake: The Unified Data Platform
Microsoft Fabric positions OneLake as the operating system for enterprise data. We break down the architecture shift from Data Lake to lakehouse.
Publisher
March 5, 2026
6 min read
From Data Lake to Lakehouse: Why the Architecture Shifted
Azure Data Lake Storage Gen2 gave enterprises a scalable, cost-effective place to land data. But landing data was never the hard part. The hard part was making that data usable — governing it, transforming it, securing it, and serving it to analysts, data scientists, and applications without building a custom integration layer for every consumer.
The result was what the industry calls the data swamp: petabytes of data stored cheaply but consumed expensively, with teams maintaining separate ETL pipelines, separate compute engines, and separate security models for each workload. Microsoft Fabric and OneLake represent a fundamental rethinking of this architecture, unifying storage, compute, governance, and security into a single platform that Microsoft now describes as the operating system for enterprise data.
OneLake: One Storage Layer for All Workloads
OneLake is the foundational storage layer of Microsoft Fabric, built on top of Azure Data Lake Storage Gen2. Every Fabric tenant gets a single OneLake instance, and every workload — data engineering, data warehousing, real-time analytics, data science, and business intelligence — reads from and writes to the same storage layer.
The architectural consequences are significant:
- No data duplication across workloads. A data engineer writes a Delta Lake table, and a Power BI report reads it directly without an import or refresh step. Direct Lake mode, now generally available, provides import-class query performance against OneLake tables with native security enforcement.
- Multi-cloud data access. OneLake shortcuts create virtual references to data in AWS S3, Google Cloud Storage, and Azure Data Lake Gen2 without copying it. The data stays where it is, but OneLake provides a unified catalog, governance layer, and access control model across all sources.
- Delta Lake as the universal format. All data written by any Fabric workload uses the Delta Lake format with full transactional guarantees. This eliminates format conversion between workloads and ensures that every consumer sees consistent, ACID-compliant data.
- Automatic schema detection. Fabric's native connectors to SQL Server 2025, Azure SQL Database, Cosmos DB, and third-party sources include automatic schema synchronization, reducing the pipeline maintenance burden that consumes a disproportionate share of data engineering effort.
Fabric as the Control Plane
At FabCon and SQLCon 2026, Microsoft made the strategic direction explicit: Fabric is becoming the central control plane for enterprise data management. This means Fabric is not just an analytics platform but the integration point for databases, AI context, governance policies, and operational workflows.
Key announcements from the conferences include Azure Databricks Lakebase reaching general availability with native OneLake reading through Unity Catalog, Runtime 2.0 incorporating Apache Spark 4.x and Delta Lake 4.x for large-scale computation, and deeper integration between Fabric and Azure AI services for embedding generation and model serving.
For enterprise architecture teams, the implication is that data platform decisions increasingly converge on Fabric as the governance and access layer, even when compute happens in Databricks, Synapse, or external tools. OneLake becomes the system of record for data location, lineage, and access policies.
Migration and Adoption Guidance
Teams currently running Azure Data Lake Gen2 with custom Spark or Synapse pipelines face a strategic choice: continue maintaining the custom stack or migrate to Fabric's managed capabilities. The evaluation should consider:
- Start with the analytics workload. If your primary pain is Power BI refresh times and data duplication, Direct Lake mode on OneLake delivers the fastest ROI. No pipeline changes required — just point Power BI at OneLake tables.
- Evaluate Fabric notebooks for existing Spark workloads. Fabric's Spark runtime is compatible with existing PySpark and Scala code. Test your most complex notebooks in Fabric's environment before committing to a full migration.
- Use shortcuts before copying. If data already lives in S3 or ADLS Gen2, create OneLake shortcuts rather than migrating data. This lets you use Fabric's governance and catalog without disrupting existing write pipelines.
- Plan governance early. OneLake's unified security model is powerful but requires upfront design. Map your existing access control patterns — who accesses what data through which tools — before enabling Direct Lake or creating cross-workload shortcuts.
- Budget for Fabric capacity units. Fabric uses a capacity-based pricing model that differs from per-query or per-node pricing in Synapse and Databricks. Model your expected workload distribution across Fabric's capabilities to avoid cost surprises.
The shift from standalone data lakes to unified lakehouse platforms is accelerating, and Microsoft's investment in Fabric signals that OneLake will be the default storage layer for Azure-based analytics within the next two years. Teams that begin integrating now will be positioned to use new capabilities as they ship rather than retrofitting after the architecture has moved on.
Sources
- OneLake, the OneDrive for Data — Microsoft Learn
- FabCon and SQLCon 2026: Unifying Databases and Fabric — Microsoft Azure Blog
- OneLake vs Azure Data Lake: Which One's Right? — Integrate.io
- Microsoft Fabric vs Databricks: 2026 Head-to-Head — Synapx